
今回の記事では、Pythonを用いて国土交通省のAPIから人口データを取得し、年齢ごとの人口分布を線で繋いだ散布図で可視化する手法を紹介します。Pythonの基本的なデータ処理や可視化手法に加え、APIとのやり取りやJSON形式のデータをフラット化してDataFrame形式に変換するポイントなど、プログラム作成の際の技術的な要点についても解説していきます。
必要なライブラリのインストールと準備
最初に、今回のプログラムに必要なライブラリの準備を行います。このコードでは、以下のライブラリを使用します。
json: JSONデータの読み書きに利用pandas: データの整理や解析に便利なDataFrameを提供matplotlib: グラフの作成numpy: 配列操作や数値計算に使用requests: APIリクエスト送信のためのライブラリmatplotlib.font_manager: 日本語フォントの設定に利用(必要に応じて設定)
import json
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import requests
from matplotlib.font_manager import FontPropertiesAPIキーとリクエスト設定
次に、APIキーとリクエストのパラメータを設定します。今回は、国土交通省が提供するAPIにアクセスし、指定した地域の人口データを取得します。座標はXYZ方式でURLより取得します。(※Zは11〜15のいずれかに設定する。)サンプルは東大阪市の座標を指定しています。
API_KEY = '****' # 自分のAPIキーに置き換えてください
url = 'https://www.reinfolib.mlit.go.jp/ex-api/external/XKT013?'
# APIリクエストの設定(XYZ座標を使用してデータ取得範囲を指定)
headers = {"Ocp-Apim-Subscription-Key": API_KEY}
params = {
'response_format': 'geojson', # データ形式を指定
'z': 15, # ズームレベル
'x': 28730, # X座標
'y': 13015 # Y座標
}
# APIリクエストの送信と応答の取得
response = requests.get(url, headers=headers, params=params)
if response.status_code == 200:
geojson_data = response.json()
else:
print(f"Error: {response.status_code}, Message: {response.text}")上記のコードでは、指定した地域の人口データをJSON形式で取得し、成功した場合にそのデータがgeojson_dataとして格納されます。取得できなかった場合はエラーメッセージが表示されます。
JSONデータのフラット化とDataFrameへの変換
次に、取得したJSONデータをフラットな形式に変換し、pandasのDataFrameに変換します。JSONデータはネスト構造になっているため、以下の関数で平坦化します。
def flatten_json(y):
"""ネストされたJSONをフラットにするヘルパー関数"""
out = {}
def flatten(x, name=''):
if isinstance(x, dict):
for a in x:
flatten(x[a], name + a + '_')
elif isinstance(x, list):
i = 0
for a in x:
flatten(a, name + str(i) + '_')
i += 1
else:
out[name[:-1]] = x
flatten(y)
return out次に、この関数を使用して全てのJSONデータをフラット化し、DataFrameに格納します。
flattened_data = [flatten_json(feature) for feature in geojson_data['features']]
df = pd.DataFrame(flattened_data)
df_data = df年代別・年齢層別の人口データの取得と整理
今回の分析対象とする年(2020年から2050年まで)を設定し、さらに年齢層を定義します。ここでは、各年齢層に対応する列名を指定し、DataFrameからデータを抽出します。
target_years = ['2020', '2025', '2035', '2040', '2045', '2050'] # 必要な年
age_groups = {
'0-4': 'properties_PT1', '5-9': 'properties_PT2', '10-14': 'properties_PT3', '15-19': 'properties_PT4',
'20-24': 'properties_PT5', '25-29': 'properties_PT6', '30-34': 'properties_PT7', '35-39': 'properties_PT8',
'40-44': 'properties_PT9', '45-49': 'properties_PT10', '50-54': 'properties_PT11', '55-59': 'properties_PT12',
'60-64': 'properties_PT13', '65-69': 'properties_PT14', '70-74': 'properties_PT15', '75-79': 'properties_PT16',
'80-84': 'properties_PT17', '85-89': 'properties_PT18', '90+': 'properties_PT19'
}年齢層別・年別の人口データの可視化(線で繋いだ散布図
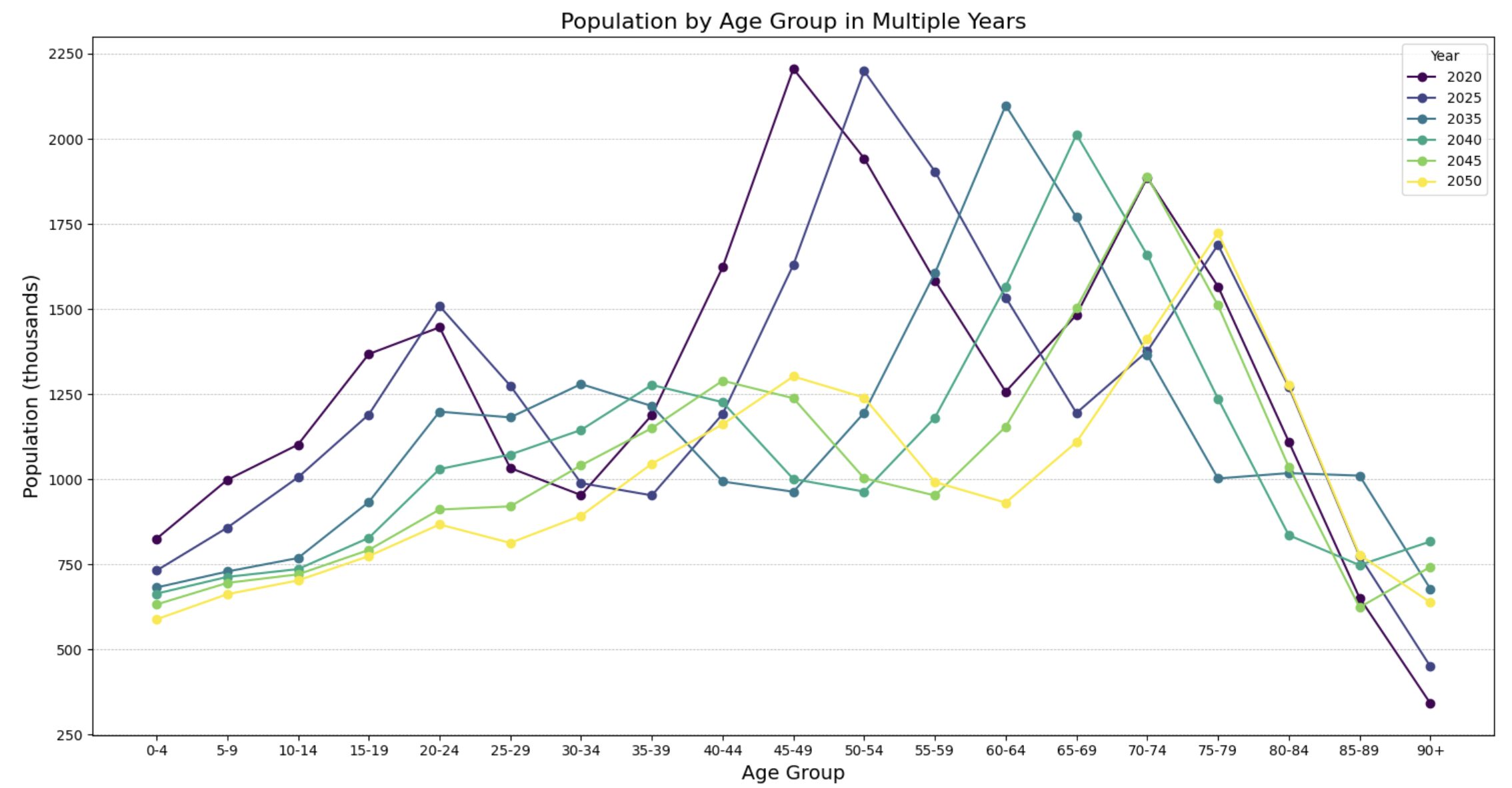
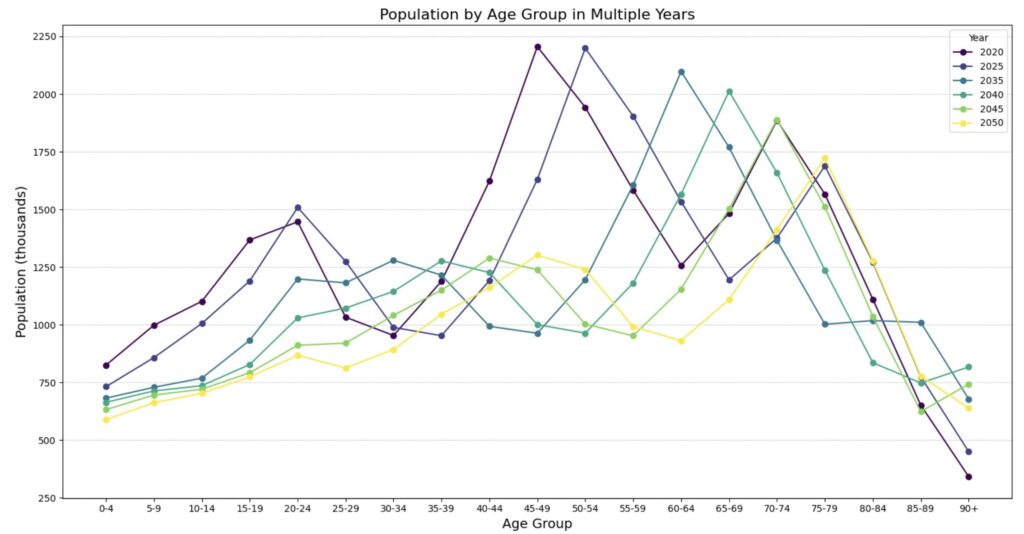
次に、各年齢層の人口分布を線で繋いだ散布図として表示するコードを作成します。ここでは、forループを用いて各年に対応する人口をプロットし、線で繋げます。
# グラフの描画設定
fig, ax = plt.subplots(figsize=(15, 8))
x = np.arange(len(age_groups))
colors = plt.cm.viridis(np.linspace(0, 1, len(target_years)))
for i, year in enumerate(target_years):
population_counts = []
for age_group_key, age_group_column in age_groups.items():
column_name = f'{age_group_column}_{year}'
if column_name in df.columns:
population_counts.append(df[column_name].sum())
else:
population_counts.append(0)
# 散布図としてプロットし、線で結ぶ
ax.plot(age_groups.keys(), population_counts, marker='o', color=colors[i], label=f'{year}', linestyle='-', markersize=6)
# グラフの装飾
ax.set_xlabel('Age Group', fontsize=14)
ax.set_ylabel('Population (thousands)', fontsize=14)
ax.set_title('Population by Age Group in Multiple Years', fontsize=16)
ax.legend(title='Year')
ax.grid(True, linestyle='--', linewidth=0.5, axis='y')
plt.tight_layout()
plt.show()上記のコードで、各年の年齢層ごとの人口データが線で繋がれた散布図として表示されます。
2050年には現役世代は半分以下になっていることが読み取れます。今新築アパートをこの地域に建てたとしたら耐用年数切れの22年後には半分になっていることからかなり厳しい状況になることが予想されます。
5年ごとの増減率計算と表示
最後に、各年齢層について5年ごとの増減率を計算し、結果を表示します。
for year_idx in range(1, len(target_years)):
prev_year = target_years[year_idx - 1]
curr_year = target_years[year_idx]
print(f"--- {prev_year}年から{curr_year}年の増減率 ---")
for age_group_key, age_group_column in age_groups.items():
prev_column = f'{age_group_column}_{prev_year}'
curr_column = f'{age_group_column}_{curr_year}'
if prev_column in df.columns and curr_column in df.columns:
prev_sum = df[prev_column].sum()
curr_sum = df[curr_column].sum()
rate_change = ((curr_sum - prev_sum) / prev_sum) * 100 if prev_sum > 0 else 0
print(f"{age_group_key}: {rate_change:.2f}%")
else:
print(f"{age_group_key}: データなし")このコードでは、指定された年ごとに年齢層別の人口増減率を計算して表示します。
--- 2020年から2025年の増減率 ---
0-4: -11.33%
5-9: -14.06%
10-14: -8.72%
15-19: -13.00%
20-24: 4.32%
25-29: 23.40%
30-34: 3.68%
35-39: -19.84%
40-44: -26.56%
45-49: -26.11%
50-54: 13.21%
55-59: 20.24%
60-64: 22.01%
65-69: -19.44%
70-74: -27.06%
75-79: 7.81%
80-84: 14.50%
85-89: 18.86%
90+: 31.75%
--- 2025年から2035年の増減率 ---
0-4: -6.79%
5-9: -15.02%
10-14: -23.57%
15-19: -21.59%
20-24: -20.56%
25-29: -7.30%
30-34: 29.42%
35-39: 27.56%
40-44: -16.64%
45-49: -40.90%
50-54: -45.65%
55-59: -15.68%
60-64: 36.78%
65-69: 48.09%
70-74: -0.71%
75-79: -40.64%
80-84: -19.95%
85-89: 30.48%
90+: 50.57%
--- 2035年から2040年の増減率 ---
0-4: -2.65%
5-9: -2.17%
10-14: -4.23%
15-19: -11.28%
20-24: -14.07%
25-29: -9.24%
30-34: -10.53%
35-39: 5.10%
40-44: 23.46%
45-49: 3.88%
50-54: -19.37%
55-59: -26.43%
60-64: -25.35%
65-69: 13.75%
70-74: 21.44%
75-79: 23.39%
80-84: -17.91%
85-89: -26.01%
90+: 20.46%
--- 2040年から2045年の増減率 ---
0-4: -4.78%
5-9: -2.47%
10-14: -2.09%
15-19: -4.29%
20-24: -11.55%
25-29: -14.18%
30-34: -9.07%
35-39: -9.94%
40-44: 5.14%
45-49: 23.72%
50-54: 4.08%
55-59: -19.38%
60-64: -26.31%
65-69: -25.33%
70-74: 13.92%
75-79: 22.15%
80-84: 24.03%
85-89: -16.59%
90+: -9.13%
--- 2045年から2050年の増減率 ---
0-4: -6.91%
5-9: -4.76%
10-14: -2.48%
15-19: -2.27%
20-24: -4.81%
25-29: -11.67%
30-34: -14.23%
35-39: -9.09%
40-44: -9.94%
45-49: 5.17%
50-54: 23.61%
55-59: 4.15%
60-64: -19.32%
65-69: -26.19%
70-74: -25.23%
75-79: 14.08%
80-84: 23.17%
85-89: 24.73%
90+: -14.01%まとめ
以上が、Pythonを用いた国土交通省APIからの人口データ取得と、そのデータを用いた年齢層ごとの人口推移の可視化および増減率計算の方法です。Pythonとデータ可視化ツールを使えば、複雑なデータも直感的に理解しやすくなります。


コメント