
はじめに
Pythonは多くのタスクを自動化できる便利なプログラミング言語で、特にデータ処理や画像操作に強みがあります。本記事では、Pythonを使って「クリップボードにある画像からテキストを抽出するツール」を作る方法について解説します。このツールは、画像の中にある文字を自動で読み取り、その内容をクリップボードにコピーするというものです。
また、OCR(光学文字認識)による精度向上のテクニックについても詳しく紹介しますので、ぜひ参考にしてみてください。
使用するPythonライブラリ
このツールを作成するために、次のPythonライブラリを使用します:
- Pillow:画像操作用のライブラリです。スクリーンショットのキャプチャや画像の前処理に使用します。
- pytesseract:OCR処理を行うライブラリです。Tesseract OCRエンジンを使って画像から文字を抽出します。
- pyperclip:クリップボードにテキストをコピーするライブラリです。
これらのライブラリは、以下のコマンドでインストール可能です。
pip install pillow pytesseract pyperclip基本コード:クリップボードの画像をOCRでテキスト化
まず、基本的なコードを紹介します。このコードでは、クリップボード内にある画像を取得し、OCRでテキストを抽出して、抽出結果をクリップボードにコピーする流れを実現しています。
範囲を選択してスクリーンショットをとるにはWindowsの場合はWindows+Shift+SでMacの場合はCommand+Shift+Ctrl+4です。
サンプルコード
from PIL import Image, ImageGrab
import pytesseract
import pyperclip
# クリップボードから画像を取得
image = ImageGrab.grabclipboard()
# 画像がある場合のみ処理を実行
if isinstance(image, Image.Image):
# OCRでテキストを抽出
text = pytesseract.image_to_string(image, lang="jpn") # 日本語に対応
print("OCR抽出テキスト:")
print(text)
# 抽出したテキストをクリップボードにコピー
pyperclip.copy(text)
print("テキストがクリップボードにコピーされました。")
else:
print("クリップボード内に画像がありません。")コードの説明
ImageGrab.grabclipboard():クリップボードから画像を取得するメソッドです。- OCR処理:
pytesseract.image_to_string()を使って画像からテキストを抽出します。 - クリップボードへのコピー:
pyperclip.copy()でテキストをクリップボードにコピーします。
これで、クリップボードの画像がOCR処理され、結果がクリップボードに保存されます。ただし、このコードのままだと認識精度に不満が残るかもしれません。そこで、次章でOCR精度を上げる方法を紹介します。
OCR精度を向上させるテクニック
OCR精度を上げるために重要なポイントは「画像の前処理」です。画像の品質やコントラスト、解像度を改善することで、OCRの認識精度が大きく向上します。
1. 解像度を上げる
解像度が低いと文字がぼやけてしまい、OCRの認識精度が下がる可能性があります。そこで、画像を一度拡大してからOCRにかける方法を試しましょう。
# 解像度の改善
image = image.resize((image.width * 2, image.height * 2), Image.LANCZOS)2. 白黒に変換
画像を白黒に変換することで、文字と背景のコントラストが強調され、OCRの認識がしやすくなります。
# グレースケール変換
image = image.convert("L")3. コントラストの強調
画像のコントラストを上げることで、文字がくっきりと見えるようになります。PillowのImageEnhanceモジュールを使ってコントラストを強調します。
from PIL import ImageEnhance
# コントラストの強調
enhancer = ImageEnhance.Contrast(image)
image = enhancer.enhance(2) # 数字を調整してコントラストを強調精度向上を取り入れたサンプルコード
以下は、上記の改善を加えたサンプルコードです。
from PIL import Image, ImageGrab, ImageEnhance
import pytesseract
import pyperclip
# クリップボードから画像を取得
image = ImageGrab.grabclipboard()
if isinstance(image, Image.Image):
# 解像度の改善
image = image.resize((image.width * 2, image.height * 2), Image.LANCZOS)
# グレースケール変換
image = image.convert("L")
# コントラストの強調
enhancer = ImageEnhance.Contrast(image)
image = enhancer.enhance(2)
# OCRでテキストを抽出
text = pytesseract.image_to_string(image, lang="jpn")
print("OCR抽出テキスト:")
print(text)
# テキストをクリップボードにコピー
pyperclip.copy(text)
print("テキストがクリップボードにコピーされました。")
else:
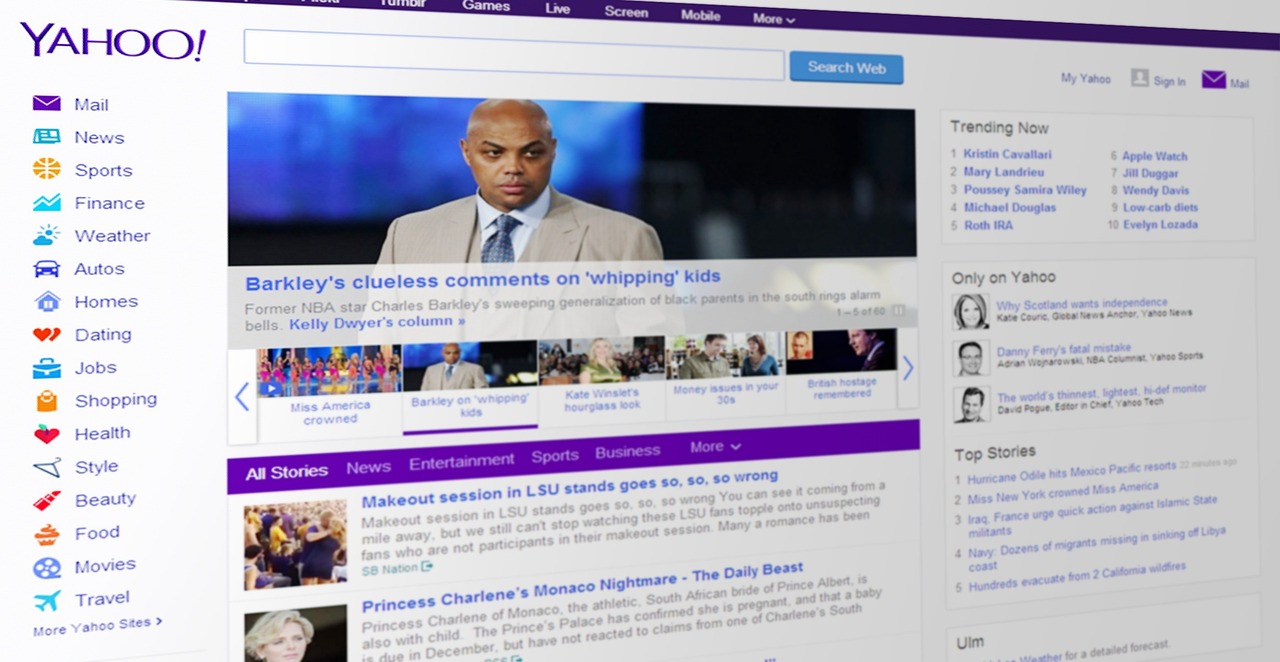
print("クリップボード内に画像がありません。")ためしにヤフーニュースの記事をOCRでテキスト化にしてみました。

<OCR結果>
第50回衆院選は27日に投開票を迎える。 与野党党首は
選挙戦最終日の26日、自民党派閥の加金問題を受けた政
治改革の必要性を各地で訴えた。自民、公明両党が過半数
(233議席) を確保できるかが最大の焦点だ。
【画像】 あなたにマッチする政党や候補者を簡単チェッ
ク! 朝日新聞ボートマッチのページ画面
今回の衆院選には、前回2021年より293人多い1344人
が立候補し、小選挙区289、比例区176の計465議席を争
う。大勢は27日深夜から28日未明にかけて判明する見通
し。所々誤変換はありますがまずまずの精度ではないでしょうか。
Tesseractの設定調整
TesseractのOCR精度は、設定次第でさらに向上します。次のオプションを試してみてください:
- ホワイトリストの設定:特定の文字のみを対象にOCRすることで精度が上がることがあります。
text = pytesseract.image_to_string(image, config="--psm 6 -c tessedit_char_whitelist=0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ")- ページ分割モードの変更:ページ全体の文字配置がわかっている場合、最適な分割モードを指定することで精度が上がります。
text = pytesseract.image_to_string(image, lang="jpn", config="--psm 6")おわりに
以上、Pythonでクリップボードの画像からOCRでテキストを抽出し、クリップボードにコピーする方法について解説しました。画像の解像度やコントラストを工夫することで、OCRの精度をかなり向上させられることがわかったかと思います。OCRを用いたデータ抽出は、さまざまな業務や日常の作業効率化に役立つため、ぜひ活用してみてください。
さらに詳細な調整が必要な場合は、画像の特徴や背景に合わせて追加の前処理を行い、より精度の高い結果を目指しましょう。

コメント